CONCUR
Benchmark for concurrent code generation by LLMs.
| # | Model | Passing Rate | CodeBLEU | ||
|---|---|---|---|---|---|
| k=1 | k=3 | k=1 | k=3 | ||
What is CONCUR?
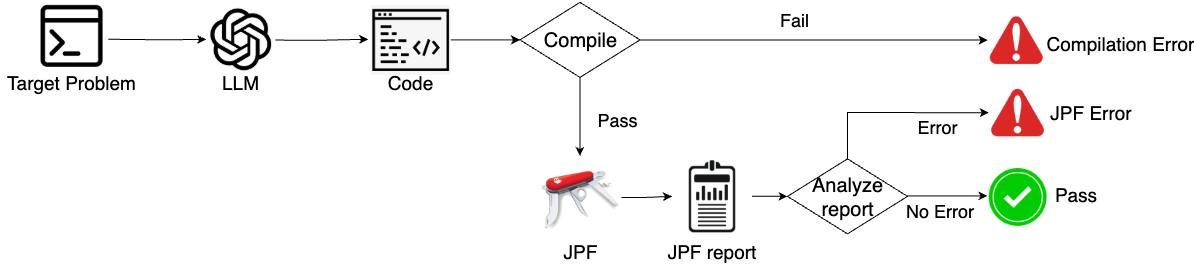
Concur is a designed for benchmarking LLMs for concurrent code generation with compilation and path execution.
What Errors Can Concur Find?
| ERROR TYPE | DESCRIPTION |
|---|---|
| Deadlock (DL) | A deadlock occurs when multiple threads are running and each thread waits indefinitely for the others to release their locks. |
| Race Condition (RC) | A race condition occurs when concurrent read and write operations are performed on the same shared variable without proper synchronization. |
| Starvation (SV) | Starvation occurs when one or more threads are perpetually denied access to shared resources because higher-priority threads monopolize execution, preventing the lower-priority threads from making progress. |
| Uncaught Exception (UE) | A range of exceptions, in addition to common concurrency errors such as deadlocks and race conditions, may arise during the execution of concurrent programs, including all exceptions defined in the Java 8 libraries. |
| No Entry Method (NEM) | This error occurs when the generated code lacks a public class with a main method, leaving no appropriate entry point for execution. |
| Single Thread (ST) | This error occurs when the generated code executes with only a single thread. This is considered incorrect, as the prompt explicitly requires the generation of multi-threaded concurrent code. |
| Termination Error (TE) | This error occurs during Java program execution in JPF. These originate not from the program itself but from JPF (e.g., failing to instantiate program variables) or from the runtime environment (e.g., system crashes caused by excessive resource usage from JPF), causing JPF to stop execution. |
Abstract
Leveraging Large Language Models (LLMs) for code generation has increasingly emerged as a common practice in the domain of software engineering. Relevant benchmarks have been established to evaluate the code generation capabilities of LLMs. However, existing benchmarks focus primarily on sequential code, lacking the ability to effectively evaluate LLMs on concurrent code generation. Compared to sequential code, concurrent code exhibits greater complexity and possesses unique types of bugs, such as deadlocks and race conditions, that do not occur in sequential code. Therefore, a benchmark for evaluating sequential code generation cannot be useful for evaluating concurrent code generation with LLMs. To address this gap, we designed a benchmark CONCUR specifically aimed at evaluating the capability of LLMs to generate concurrent code. CONCUR consists of 43 curated concurrency problems and leverages formal methods techniques, namely model checking, to assess the correctness of the generated code. We conducted an evaluation of a range of LLMs on CONCUR, highlighting limitations of current models. Overall, our work provides a novel direction for evaluating the capability of LLMs to generate code with focus on concurrency.
Code Evaluation Framework of CONCUR.